数理最適化の勉強メモ − 最急降下法 / ニュートン法の原理と特徴
数理最適化の勉強メモその2です。
前回の記事では、数理最適化の基本的な事項として解析的な解法、最適性条件、最適化がうまくいかない条件などについてまとめました。
今回の記事では、具体的な数値最適化のアルゴリズムとして、直線探索法の一種である最急降下法とニュートン法についてまとめてみたいと思います。
※ 2019/09/22 : 前回の記事が長くなりすぎたので後半部分をこの記事に分割しました。
スポンサーリンク
もくじ
0. 解きたい問題
今回の記事では前回に引き続き、数理最適化の分野の中でも微分可能な制約なし連続最適化問題(unconstrained continuous optimization)と呼ばれる、以下のような問題の局所的最適解の1つを求めることを目標にします。
ここで目的関数 は2回連続微分可能であり、値が変化しない平らな領域(1階微分係数と2階微分係数が継続的に
になる領域)を持たないものとします。
平たく言えば、ベクトル に対してなだらかに変化する関数
が、最も小さな値を取る点
を求めます。
ただ、真に最も小さくなる点(大域的最適解)を求めるためには、あらゆる
を調べる必要があって難しいです。
そこでとりあえずは、ボウルの底のように周りより値が小さくなっている点(局所的最適解)を1つ求めてみる、ということを目標とします。 実用的な問題では、局所的最適解=大域的最適解であることも多いですし、複数の局所的最適解がある場合もこの考え方を応用したアルゴリズムを使うので、まずはこの方法を考えるのです。
1. 直線探索法とは
連続関数の最適解を求める手法は関数の形に応じて色々ですが、今回は最も汎用的な手法として、反復法の中の直線探索法(line search method)というアルゴリズムを紹介します。
反復法は、適当な初期解 から
の値が小さくなる方向に少しずつ解を動かしていき、これ以上小さくならなくなったら(勾配ベクトルが
になったら)そこを局所的最適解とみなす、というアルゴリズムです。
※ を評価する代わりに
を評価することもあるようです。前回の記事に従えば、鞍点に収束することを避けるために
が正定値行列になっているかを確認すべきなのですが、低い方向を辿っていく過程でピンポイントに鞍点に乗り上げてしまう可能性はかなり低いです。そのため、一般的には勾配ベクトルの大きさだけで収束判定を行います。
そして反復法のうち、先に探索方向 を決めてからその方向を探索し、ちょうど良さそうな更新幅
を見つけて、
のように解を更新する手法を直線探索法といいます。
ここで問題になるのが、
- どのように探索方向
を決めるか
- 効率を上げるため、なるべく最適解がある方向を探索したい
- どのように更新幅
を決めるか
- 関数のスケールがわからないので、雑に更新幅を決めてしまうと、収束しなかったり見当違いの場所に飛んでいったりする
の2つです。
1つ目の探索方向の決め方として有名なのが、今回紹介する最急降下法とニュートン法です。
2つ目の更新幅の決め方としては、Wolfe条件に基づいたアルゴリズムを使うのが一般的です。
解説の都合上、Wolfe条件の方から見ていきます。
2. 更新幅の決め方(Wolfe条件)
直線探索における更新幅の決め方にはいくつかバリエーションがあるのですが、最もよく使われるのがWolfe(ウルフ)条件を利用したアルゴリズムです。
Wolfe条件は、以下のArmijo(アルミホ)条件と曲率条件の2つから成ります。
2.1. Armijo条件
Armijo条件は、ざっくり言えば値を増加させないための条件です。
右辺の式は のときに
の接線の式となり、
のときは
の軸に平行な線となります。
つまり、この条件は
を遠くに設定するほど
がしっかり減少していなければならない、という条件であると言えます。
値がどの程度減少すべきなのかを決めるパラメータが です。
2.2. 曲率条件
曲率条件は、ステップ幅をある程度大きく取るための条件です。
Armijo条件を確実に守るためには をどんどん小さく設定すればいいのですが、それでは解が全く更新されなくなってしまいます。
そこで、直線探索法のそもそもの目的「勾配ベクトル
が
になる場所を探す」に当てはめて、今の場所より勾配が緩やかな場所でなければならない、という条件を課しているのが曲率条件です。
勾配がどれくらい緩やかであるべきかを決めるパラメータが です。
以上の2条件を満たす を使用し続ける場合、1回連続微分可能かつ1階導関数がリプシッツ連続であるような目的関数(2回連続微分可能よりゆるい条件、詳しくは他の文献を参照)についての直線探索法は「どこからスタートしてもどこかに収束すること」(大域的収束性)が保証されます。
つまり、有限な反復回数でどこかの局所的最適解には辿り着くことが保証されています。
2.3. 更新幅を決めるアルゴリズム
このWolfe条件を満たすような の求め方についていくつか文献を漁ってみたのですが、ちゃんとした手順は紹介されていませんでした。
おそらくですが、事前に最大ステップ幅 とステップ幅を縮小する係数
およびWolfe条件のパラメータ
を与えておき、
がWolfe条件を満たすまで
をインクリメントする、というようなアルゴリズムを使うのではないかと思います。
3. 最急降下法
それでは、肝心の探索方向の決め方について見ていきましょう。 まずは最急降下法(steepest descent method)の紹介です。
最急降下法という名前自体は離散最適化の分野でも使われていますが、連続最適化の分野では、直線探索法において探索方向を決めるアルゴリズムの1つを指します。
最急降下法では、 の周りで
を1次多項式(直線・平面・超平面)に近似し、一番急な方向
を探索方向として選びます。つまり「一番勾配が急な方向を探索する」という戦略です。
たとえば、前回の記事でも使った2変数関数 について、
における近似平面と探索方向
を可視化すると以下のようになります。
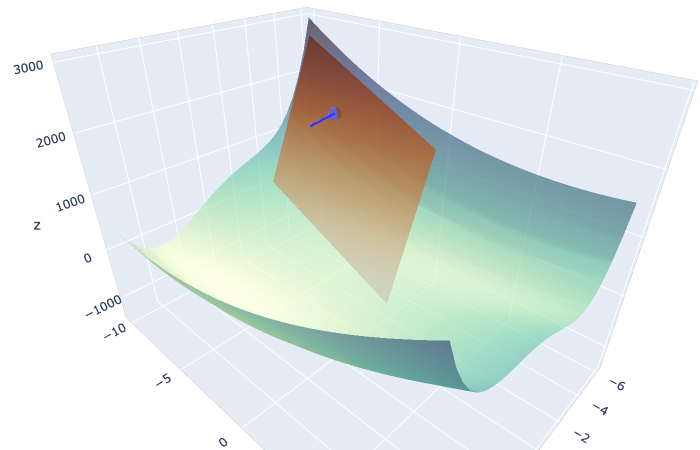
3Dグラフはこちら : https://kamino410.github.io/cv-snippets/optmz_blog/steepest.html
ステップ幅を大きく取る場合、このまま に収束しそうですね。
ステップ幅を小刻みに取る場合は、
の方に収束するかもしれません。
最急降下法は確実に値を減らしていくことができる堅実な手法ですが、1次収束であり、局所的最適解にたどり着くまでに必要な反復回数が多くなりやすいことが知られています。 たとえば、上から見たときの等高線が楕円状であるような関数で最適化をするとき、ほとんどの場所で勾配ベクトルは楕円の中心とは違う方向を向きます。 この関数のように、1次項の成分より高次項の成分が勝っているような関数では、最急降下法の収束は非常に遅くなります。
4. ニュートン法
最急降下法の収束性の悪さを改善するために提案されたのがニュートン法(Newton's method)です。
最急降下法では、勾配が最も急な方向を探索方向としていました。一方、ニュートン法では の周りで
を2次多項式に近似し、その2次多項式の最適解がある方向を探索方向とします。つまり「より近似精度の高い式を立てて、その最適解がある方向を探せば、実際の最適解にも早く近づけるだろう」という戦略です。
は2次までのテイラー展開を考えることで、以下のような2次多項式に近似できます。
もし が正定値行列なら、近似式は凸関数である(つまり下向きにボウル状になっている)ので、最小解は一意に決定できます。最適解は勾配ベクトルが0となる点であることに注意すると
が停留点であることがわかります。
そこで、ニュートン法では を探索方向として採用します。
先ほどと同じ目的関数について、 における近似関数と探索方向
を可視化すると以下のようになります。

3Dグラフはこちら : https://kamino410.github.io/cv-snippets/optmz_blog/newton1.html
最急降下法のときより高い精度で目的関数を近似できていることがわかります。
における近似2次多項式の停留点は極小点
であるため、探索ベクトルはそちらの方向を向きます。
数回の反復で
に収束しそうですね。
このように、ニュートン法では目的関数を精度良く近似できるため収束が早いです(2次収束)。そのため、最急降下法よりはるかに少ない反復回数で局所的最適解に辿り着けることが知られています。
ただし、ニュートン法には、ヘッセ行列 が正定値でないときに近似された2次多項式が凸関数でなくなるため、求めた停留点が鞍点や極大点になってしまうという欠点があります。
たとえば、 における近似2次方程式は鞍点
を停留点とする非凸関数となります。この方向を探索すると、しばらく値が増加したあと山の向こうを下っていくことになりますが、局所的に値が増加する方向を探索することは、勾配法の趣旨に反しています。よって、非凸関数に近似されたときは特別な処理が求められることになります。

3Dグラフはこちら : https://kamino410.github.io/cv-snippets/optmz_blog/newton2.html
また、 自体の計算と1次連立方程式
を解くための計算コストが高いこともニュートン法の課題です。対称行列であるヘッセ行列は対称行列は、変数
の次数に対して計算すべき要素の数が
もありますし、1次連立方程式の計算もそれ以上にコストが高いです。
つまりパラメータ数に対してどんどん処理が重くなります。
これらの課題を克服するため、ヘッセ行列 をいいかんじの正定値行列
で近似する準ニュートン法というアルゴリズム群が提案されています。
準ニュートン法については、また気が向いたときに勉強メモを公開できたらいいなと考えています。
5. 実装上の留意点
最後に、直線探索法を実装する上で注意した方がよさそうな点をまとめておきます。
5.1. 最適性条件
まず、最適性条件として利用する もしくは
の閾値
をどの程度小さくすればいいのかという問題です。
大きすぎれば真の最適解から離れた場所で収束判定されてしまいますが、小さすぎると数値計算上の誤差が閾値を上回り、いつまでたっても収束判定されないという事態が起こります。
理想的な閾値 は
のスケールや関数の形に依存するので、試行錯誤しながら手作業で決めることが多いです。
5.2. 数値微分
数値最適化を計算機に解かせるとき、勾配ベクトル やヘッセ行列
をどうやって計算するのかという問題があります。
素直に考えれば、1階導関数や2階導関数は微分の定義を利用して数値的に計算することになります。
1つ目の式は前進差分、2つ目の式は後退差分、3つ目の式は中央差分と呼ばれます。
同じ に対して微分値を計算したときの精度は中央差分が一番高くなることが証明できるのですが、中央差分は
と
の2つを計算する必要があるので少し計算コストが高くなります(
はどちらにせよ計算する必要があるので計算コストに見込まない)。
とはいえそこまで計算コストが高いものではないので中央差分を採用することが多いです。
さて。
ここでも をどの程度まで小さくすればいいのかという問題が生じます。
あまり小さくしても、数値計算上の誤差のせいで逆に精度が悪化していくからです。
『数値計算の常識 第8章 数値微分法』によれば、 を計算する上で見込まれる誤差を
として、おおよそ
を満たすような
を使うのが良いそうです。
適当に を
程度と仮定して、double型の浮動小数点の仮数部が52ビットであることからこれまた適当に
と仮定すると、
です。
結局、大雑把に有効桁数の半分程度を選べばいいようです。
【2019/10/23 追記】
また、目的関数がcos, atan, powなどのよく使われる数学関数(厳密には実係数多項式の合成関数)だけで記述される場合は、このような数値計算をせずとも解析的な考え方に基づいて導関数を求めることができます。
線形代数ライブラリのEigenやGoogleが開発している最適化ライブラリであるceres-solverでは、双対数(dual number)という多元環を利用して導関数の値を計算する自動微分が実装されています。 詳細は以下の記事にまとめているので気になる方は参照してみてください。
5.3. 実用的な実装
このように、数値最適化のアルゴリズムを実装するためには意外と奥深い知識が要求されます。 また先ほど説明したように、実用的には今回紹介した最急降下法やニュートン法よりBFGS法などの準ニュートン法を使うことの方が多いでしょう。 もし目的関数が最小二乗の形になっているのであればLevenberg-Marquardt法やDogleg法が選択肢に入ってきます。
これらの手法の実装はかなり複雑になります。 勉強用ならともかく、実用的にはMATLAB, Eigen, Scipy, Ceres Solverなど既存のライブラリを活用するほうが懸命だと思います。
ライブラリ内部で行われている処理を理解する上でこの勉強メモが役に立てば幸いです。
以上、数値最適化について勉強したことをまとめてみました。
次の記事では非線形最小二乗法でよく使われるLM法の解説をしているので良ければ併せて読んでみてください。
このメモを書くに当たって以下の文献にお世話になりました。 ありがとうございました。
- NOCEDAL, Jorge; WRIGHT, Stephen. Numerical optimization Second Edition. Springer Science & Business Media, 2006.
- 伊理正夫; 藤野和建. 数値計算の常識. 1985.
- 矢部博. 工学基礎最適化とその応用. 数理工学社, 2006.
- 最適化手法についてー勾配法,ニュートン法,準ニュートン法などー | moskomule log