【C++】リアルタイムな処理をパイプライン化してフレームレートを改善してみる
今回の記事では、リアルタイムなデータ処理を高いフレームレートで実行するため、マルチスレッドなパイプラインをC++で実装してみます。
シンプルな実装例から、ダブルバッファリングを用いた実装例やスレッドプールを用いた実装例もご紹介します。
実装したコードは、こちらのGitHubリポジトリにまとまっています。
もくじ
スポンサーリンク
1. 今回の目的
コンピュータビジョンやARのアプリを開発していると、カメラ画像に何らかの処理を施し、それに応じて何らかの出力を出す、という実装をする場面がたくさんあります。 また、IoTやエッジコンピューティングの世界でも、リアルタイムに得られるセンサー情報を逐次的かつ高速に処理したい場面は多くあります。
こうしたアプリでは、1秒間に出力を何回アップデートできるか(フレームレート)と、データが取得されてから出力が出るまでにどれだけの時間がかかるか(レイテンシー)の2つがアプリの性能を評価するポイントになります。 現実とシンクロさせるためには、フレームレートを高く、レイテンシーを短くするのが理想です。
一般的に、処理の複雑さとレイテンシーはトレードオフの関係にあり、どれだけ単純かつ並列化可能なアルゴリズムで目的を達成するかが、レイテンシーを減らすポイントになります。
一方、フレームレートについては、処理をパイプライン化することでアルゴリズムの改善なしに高速化することができます。
ここで言うパイプライン化とは、処理をいくつかの単位に分割し、それぞれを並列に実行することです。 イメージとして、工場の流れ作業を想像してもらえば良いと思います。
例えば、ARマーカーの上にオブジェクトを表示するARアプリなら、①カメラから画像を取得する処理、②画像からARマーカーの位置を検出する処理、③ARマーカーの位置に応じてオブジェクトをレンダリングする処理、の3つに分割して並列に実行すれば、フレームレートを改善できるでしょう。
今回の記事では、パイプライン処理を実装する上での注意点や、いくつかの実装例を紹介してみたいと思います。
2. マルチスレッド実装の泣きどころ
前置きとして、マルチスレッドの実装は意外に大変だ、という話を書いておきます。
今回はマルチスレッドなパイプライン処理を実装するので、当然ながらスレッドレベルの並列処理の実装が必要になります。
マルチスレッドプログラミングでは、一般的に以下の現象に注意しなければならないと言われています。
- データ競合(data race)
- 競合状態(race condition)
- 複数のスレッドが協調して動いているなか、何らかの原因で一方のスレッドの処理が遅れたときに処理の順番が入れ替わってしまい、意図したものと異なる実行結果になること
- デッドロック(deadlock)
- 複数のスレッドがお互いの処理待ち状態になることで、処理が止まってしまう現象
- 競合状態の結果、デッドロックに陥る可能性がある
C++では、これらの現象を避けるため、atomic変数やmutexを利用した排他的処理の仕組みが用意されています。
また、今回は解説が複雑になるので利用を避けますが、future,promiseを用いたマルチスレッド実装のパターンも用意されています。
この記事の本題はパイプライン処理の実装なので、問題の詳細や解決できていることの証明は省きます(というより、著者も深い話ができるほどの知識がありません笑)。 要所要所で解説を入れますが、詳しい話は他の文献を参照してください。
3. 問題設定
本題です。
この記事では話を単純化するため、入力データに処理Xと処理Yを順番に施して出力を得たいというシチュエーションを考えます。 また、入力データは処理Xがいつでも取得できると仮定します。

単純にこの処理を順番に施す場合、X+Yの周期で処理が実行されることになります。
この周期では満足できないので、処理Xを担当するスレッド1と処理Yを担当するスレッド2を走らせてパイプライン化してみよう、というのが今回の目標です。
しかし、スレッド1からスレッド2にデータを渡す場合、上で説明したようなデータ競合に配慮しなければなりません。 スレッド1の書き込みとスレッド2の読み込みの間は、データをロックして相手がアクセスできない状態(排他的処理)にしなければならないのです。
これを考慮するため、処理Xと処理Yを以下のように分割して考えることにします。
- スレッド1の処理
- 処理A: スレッド2と同時実行可能な部分
- 処理B: データ競合を避けてデータを書き込むために排他的処理が必要な部分
- スレッド2の処理
- 処理C: データ競合を避けてデータを読み込むために排他的処理が必要な部分
- 処理D: スレッド1と同時実行可能な部分

つまり、素のままではA+B+C+Dである周期をできるだけ短くするのが今回の目標です。
ちなみに、レイテンシーの改善はパイプライン化ではどうにもならないので、処理A,B,C,Dのアルゴリズムを改善して処理時間自体を短くするしかありません。
4. ナイーブな実装例
まずはシンプルな実装例として、mutexを用いて排他的処理を実現した例を見ていきましょう。
4.1. ソースコード
処理BとCはmutex_1to2をロックしてから、data_1to2にアクセスすることで排他的処理を実現しています。
今回data_1to2はint型なので、std::atomic<int>として宣言すれば自動的に排他的処理が施されるのですが、一般的には渡すデータがatomicとして宣言できる型とは限らないため、ここではmutexを採用しています。
{ std::lock_guard<std::mutex> lock(mutex_1to2); }はmutexをロックした後、アンロックするのを忘れないための構文です。
このようにロックしておくと、変数lockがスコープから外れてデストラクタが実行されるタイミングで勝手にアンロックされるため、実装がラクになります。
スレッド1は、処理AのダミーとしてTASK_A_COST[μs]だけ待ってから、処理BでTASK_B_COST[μs]かけてdata_1to2に1ずつインクリメントしたidを格納しています。
スレッド2は、処理CでTASK_C_COST[μs]かけてdata_1to2を読み出したあと、処理DのダミーとしてTASK_D_COST[μs]だけ待ってから、次のデータに備えます。
次のデータが来ないうちに処理を開始しないよう、flag_update1to2を通して新しいデータであるかどうかを確認してから処理を開始しています。
実のところflag_update1to2を何度も確認するのは計算量的にはよろしくなく、理想的には後述のcondition_variableを使って通知を送るべきなのですが、実装がさらに複雑になるので、ここではナイーブな実装に留めています。
各処理は実行時間を測定し、プログラムの最後にログを出力するようにしています。
それでは、各処理の処理時間を変えながら、いくつか実験をしてみましょう。
4.2. 実験1: 上流の処理(A+B)が重いケース
まず、上流の処理が重い例として、各タスクの処理時間を以下のように設定して実行してみます。
TASK_A_COST: 1000TASK_B_COST: 100TASK_C_COST: 100TASK_D_COST: 500
※ なお、std::this_thread::sleep_for()はあくまで「指定された時間以上が経過していることを保証する」という仕様のため、待ち時間は厳密にこの通りになるとは限らず、多少待ち時間が長くなることもあります。上の数値と以降の実行結果が一致しないのはこれが原因です。
各処理の実行時間を可視化したのが以下のガントチャートです。
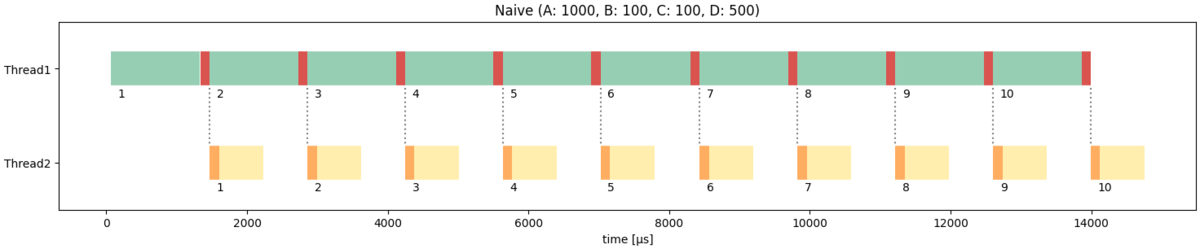
スレッド1とスレッド2が並列に実行されており、目論見通りのパイプライン処理が実現できていることがわかります。 出力の周期はA+Bで、レイテンシーはA+B+C+Dです。
このように、渡すデータの書き込み・読み込み(B,C)が軽く、最初のスレッドの処理が最も重いケース(A+B > C+D)では、この素直な実装で十分目的を果たせます。 これは3つ以上のスレッドに分割する場合も同じで、常に上段の処理のほうが重いことが保証されるなら、パイプライン処理はナイーブな実装で十分です。
4.3. 実験2: 排他的処理(B,C)が重いケース
次に、排他的処理の時間が長いケースとして、各タスクの処理時間を以下のように設定して実行してみます。
TASK_A_COST: 100TASK_B_COST: 600TASK_C_COST: 500TASK_D_COST: 100
これは、そもそもスレッド1が大量のデータを書き込むこと(e.g. カメラからの画像取得)を目的としていて、mutexを専有する時間(処理B)が長くなるようなケースを想定しています。
カメラから取得した画像をdata_1to2に直接書き込む場合、カメラのAPIが画像取得処理を終えるまでmutexをロックせざるを得ないのでBの時間が長くなる、ということです。

このケースでは、周期がB+C(D > BならC+D)となり、レイテンシーはA+B+C+Dとなります。 周期とレイテンシーは安定しますが、スレッド1とスレッド2がお互いを待つ時間が長いため、A+Dの処理時間分しかパイプライン化の恩恵がありません。
こうしたケースでは、以降で紹介するダブルバッファリングを使えばフレームレートを改善できる可能性があります。
4.4. 実験3: 下流の処理(C+D)が重いケース
最後に、下流の処理が重い例として、各タスクの処理時間を以下のように設定して実行してみます。
TASK_A_COST: 500TASK_B_COST: 100TASK_C_COST: 100TASK_D_COST: 1000
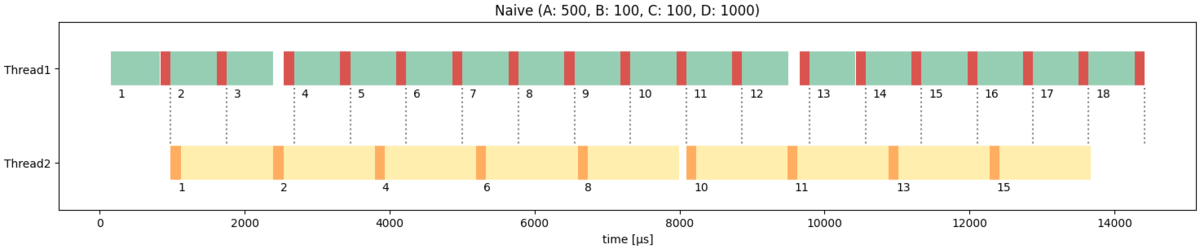
スレッド2が全てのデータを処理できず、id = 3, 5, 7, 9, 12, 14が飛ばされてしまっていることがわかります。
また、処理Bと処理Cのタイミングが重なったときにmutexの排他的処理待ちが発生し、スレッド1,2ともに周期が乱れていることもわかります。 そのため、出力の周期はC+D+αとなっています。
また、レイテンシーもid = 1に関してはA+B+C+Dですが、id = 2のときは2A+B+C+D近くまで伸びており、一定でないことがわかります。
このように、下流の処理の方が重い場合、ナイーブな実装では周期やレイテンシーが一定にならず、流したデータが全て出力に反映されないという状況になります。
このケースではいくつかの対応策が考えられます。
1つ目は、周期やレイテンシーの乱れを無視してそのまま使う、というものです。 周期やレイテンシーが一定でなくても困らない、というアプリケーションなら、この実装でも十分です。
2つ目は、スレッド1にsleep_forを挟むなどして、意図的に上流の処理を重くするという方法です。
上で見たように、上流の処理が重いときは周期A+BかつレイテンシーA+B+C+Dで安定するので、周期A+B+C+Dであった当初よりはフレームレートが改善されます。
3つ目は、下流の処理をスレッド2だけでなく複数のスレッドで処理してしまう、という方法です。 例えば、idが奇数のときを担当するスレッド2と、偶数のときを担当するスレッド3を用意すれば、単純計算で2(A+B) < C+Bの条件までカバーできます。 この考え方を汎化したのが、以下で説明するスレッドプールです。
5. ダブルバッファリングを用いた実装例
ここまでの実験から、ナイーブな実装は処理Bが重いときや下流の処理が重いときに問題を生じることがわかりました。
このうち、処理Bが重いときの方策として、ダブルバッファリングを用いる方法があります。
ダブルバッファリングは、容量が大きなデータを受け渡しするときに使われる手法です。 理屈は単純で、2つのデータ領域を用意して一方に書き込む間にもう一方から読み出し、受け渡しのときはお互いを交換します。 こうすることで、データ競合を避けつつ書き込みと読み込みを同時に実行できます。
5.1. ソースコード
今回は、自前でDoubleMutexというダブルバッファリング用のmutexを用意して排他的処理を実装してみました。
swap()をどちらのスレッドのどのタイミングで呼び出すかによって全体の挙動が変わってくるのですが、今回は上流の書き込み処理(処理B)が重いことを想定して、unlock_write()の直後に呼び出しています。
swap用のスレッドを別に用意して、書き込み・読み込み両方が終わったタイミングでswapする方法もありますが、今回はわかりやすさを優先してこのような実装にしました。
5.2. 実験: ダブルバッファリングの効果
実験2と同じ条件で試してみます。
TASK_A_COST: 100TASK_B_COST: 600TASK_C_COST: 500TASK_D_COST: 100
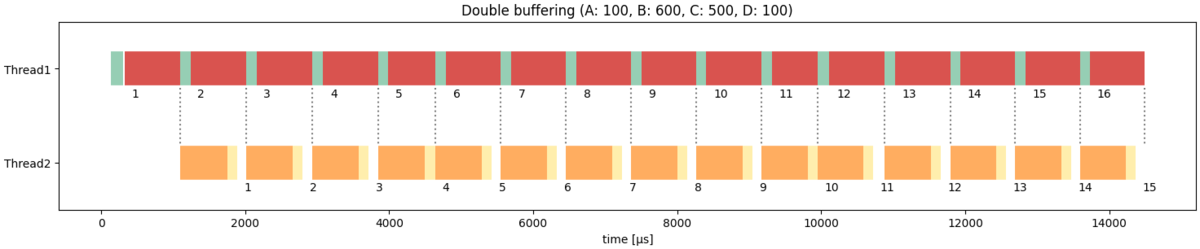
先ほどは周期がB+Cでしたが、処理BとCを同時進行できるようになったおかげで、周期がA+Bまで改善されていることがわかります。
このように容量が大きなデータを扱う場合でも、工夫次第ではフレームレートを改善できます。
6. スレッドプールを用いた実装例
最後に、下流の処理が重いときの方策として、スレッドプールを用いた実装例を紹介します。
この実装では、下流の処理をスレッド2だけでなく複数のスレッドに分担させることで、下流の処理の周期を短くします。
例えば、SLAMはリアルタイムな動作が必要にも関わらず、下流の画像の特徴量抽出やbundle adjustmentが重くなりがちなため、スレッドプールがよく利用されています。
6.1. ソースコード
スレッドプールでは、データを複数のスレッドが同時に処理することになるため、ダブルバッファリングのときと同様に複数のバッファーを用意してスレッド間でやり取りする必要があります。
今回は、バッファーのアドレスを未使用キューbuffers_1to2_freeと使用中キューbuffers_1to2_usedに分類して格納しています。
スレッド1は、未使用キューからバッファーを1つ取り出し、データを書き込んでから使用中キューに追加します。
その後、std::condition_variableの機能を利用して、待機しているスレッド2の1つに通知を送ります。
一方、スレッド2はスレッド1からの通知が来るまで待機し、通知が来たらbuffers_1to2_usedからバッファーを取り出して処理を開始します。
処理が完了したら、使ったバッファーを未使用キューに戻し、また次の通知が来るまで待機するようになっています。
なお、今回の実装では通知が無視されてしまったときのエラーハンドリングを書いていないので、もし通知のタイミングで空いているスレッド2がなければ、データの整合性が取れなくなります。 スレッド2が何らかの理由で遅くなる可能性があるなら、スレッド2の数を増やすか、エラー処理を実装しておくべきだと思います。
6.2. 実験: スレッドプールの効果
実験3と同じ条件で試してみます。
TASK_A_COST: 500TASK_B_COST: 100TASK_C_COST: 100TASK_D_COST: 1000
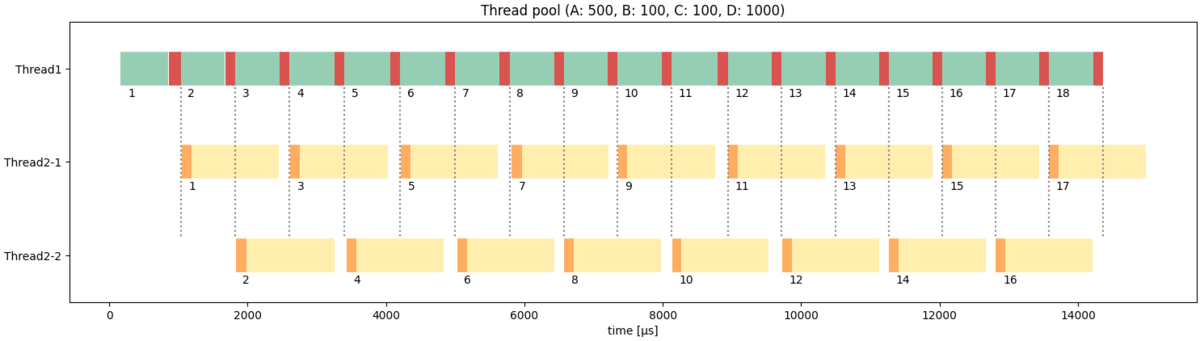
先ほどはスレッド2が全てのデータを処理できず、周期とレイテンシーも不安定になっていました。
一方、今回は2つのスレッド2が交互にデータを処理することで、周期がA+B、レイテンシーがA+B+C+Dで安定しています。
実装が複雑になることと、若干のオーバーヘッドが乗ることを除けば、スレッドプールによる実装は非常に優秀だということがわかります。
以上、パイプライン化によってリアルタイム処理のフレームレートを改善する方法をまとめてみました。
あまり文献がない話題だと思うのですが、他にいい手法があればぜひ教えて下さい!